Füzi, B., Malik-Sheriff, R.S., Manners, E.J. et al. KNIME workflow for retrieving causal drug and protein interactions, building networks, and performing topological enrichment analysis demonstrated by a DILI case study. J Cheminform 14, 37 (2022)
DOI
https://doi.org/10.1186/s13321-022-00615-6
Abstract
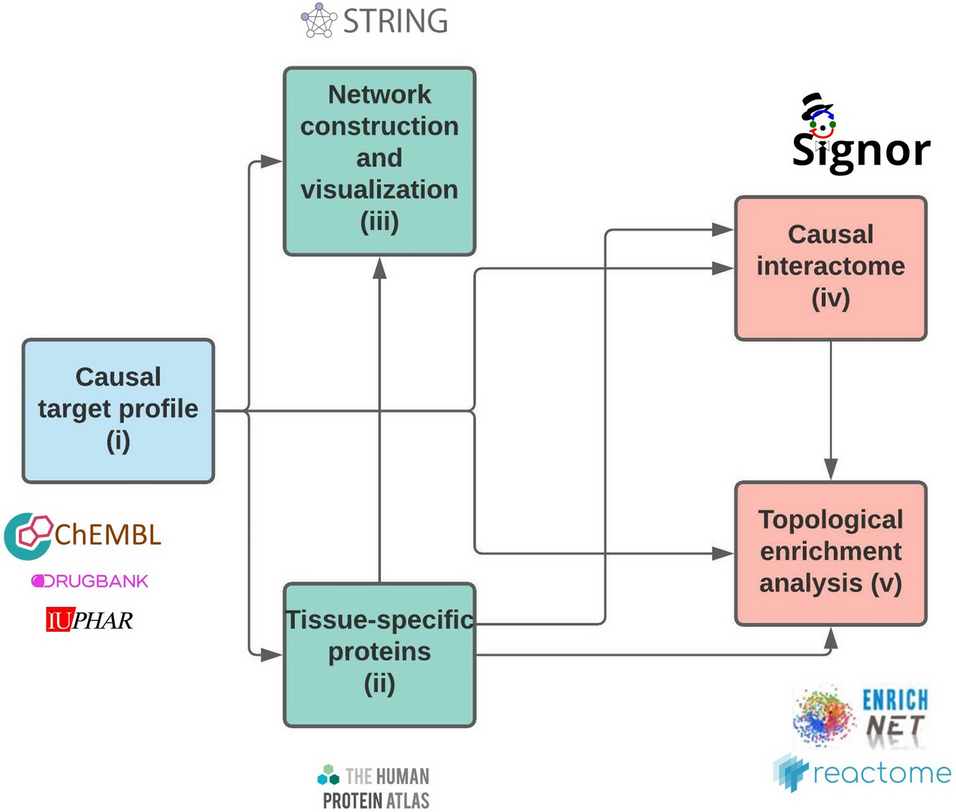
As an alternative to one drug-one target approaches, systems biology methods can provide a deeper insight into the holistic effects of drugs. Network-based approaches are tools of systems biology, that can represent valuable methods for visualizing and analysing drug-protein and protein–protein interactions. In this study, a KNIME workflow is presented which connects drugs to causal target proteins and target proteins to their causal protein interactors. With the collected data, networks can be constructed for visualizing and interpreting the connections. The last part of the workflow provides a topological enrichment test for identifying relevant pathways and processes connected to the submitted data. The workflow is based on openly available databases and their web services. As a case study, compounds of DILIRank were analysed. DILIRank is the benchmark dataset for Drug-Induced Liver Injury by the FDA, where compounds are categorized by their likeliness of causing DILI. The study includes the drugs that are most likely to cause DILI (“mostDILI”) and the ones that are not likely to cause DILI (“noDILI”). After selecting the compounds of interest, down- and upregulated proteins connected to the mostDILI group were identified; furthermore, a liver-specific subset of those was created. The downregulated sub-list had considerably more entries, therefore, network and causal interactome were constructed and topological pathway enrichment analysis was performed with this list. The workflow identified proteins such as Prostaglandin G7H synthase 1 and UDP-glucuronosyltransferase 1A9 as key participants in the potential toxic events disclosing the possible mode of action. The topological network analysis resulted in pathways such as recycling of bile acids and salts and glucuronidation, indicating their involvement in DILI. The KNIME pipeline was built to support target and network-based approaches to analyse any sets of drug data and identify their target proteins, mode of actions and processes they are involved in. The fragments of the pipeline can be used separately or can be combined as required.
Funding
This work has received funding from the Innovative Medicines Initiative 2 Joint Undertaking under grant agreement number 116030 (TransQST). This Joint Undertaking receives support from the European Union’s Horizon 2020 Research and Innovation Programme and European Federation of Pharmaceutical Industries and Associations (EFPIA). This work was also supported by the Austrian Science Fund/FWF, grant W1232 (MolTag) and EMBL core funding. This research was funded in part, by the Wellcome Trust [104104/A/14/Z and 218244/Z/19/Z]. We also acknowledge funding from the Member States of the European Molecular Biology Laboratory.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.